Contact the Stake Casino Australia review desk
How to send clear support requests and evidence packs so your Stake Casino Australia issue is reviewed faster with less back-and-forth on payouts and bonuses.
- 🧾 Include transaction ID and timestamp
- 🎯 Ask one concrete question per message
- 🧵 Keep all updates in the same ticket thread
📌 How to open a high-signal support ticket
🔍 First message structure
The strongest first message is short and factual: what happened, when it happened, how much was involved, and what exact outcome you need. Support agents work faster when they can classify a case instantly. Long emotional context may feel honest, but it usually slows triage and pushes the ticket into generic templates. Treat the first line like a case summary, not a diary entry.
I also avoid opening duplicate chats for the same issue. Multiple channels split context and force re-validation, which adds delay. One channel with complete evidence is almost always faster than scattered messages across live chat and email.
✅ Example checklist
Before sending, confirm these fields are present: amount, method, account state, and event timestamp. If it is a game issue, include game name and round marker. If it is payout-related, include withdrawal request time and status screenshot. This basic structure dramatically improves answer quality.
📌 Evidence pack format for payout and bonus disputes
🔍 What to attach first
Attach only high-signal artifacts: one clean screenshot of the status state, one transaction reference, and one concise chronology. Too many mixed screenshots reduce readability and increase back-and-forth. The objective is to make verification effortless for the next reviewer in queue.
For bonus issues, include offer snapshot and the exact point of failure (missing credit, blocked conversion, or condition mismatch). For payout issues, include route consistency details and prior verification confirmation if available. This turns complaints into resolvable cases.
✅ Timing discipline
If no response in the promised window, follow up once with new evidence instead of re-sending the same paragraph. Repetition without new data rarely accelerates outcomes. Structured escalation does.
📌 Escalation ladder and follow-up cadence
🔍 Escalate without noise
Escalation should be calm and specific: reference original case ID, summarize unresolved point, request next-level review. Avoid rewriting the full story each time. Agents and supervisors both work faster when continuity is preserved.
My practical cadence is simple: first request, one bounded wait window, then one escalation with evidence delta. If that still stalls, request explicit timeline ownership. This keeps pressure professional and defensible.
✅ Why this works
Support operations reward clarity. A clean thread helps internal handoffs and reduces context loss between shifts. You are not just asking for help; you are making resolution easier to execute.
📌 Case closure and post-resolution notes
🔍 Close the loop intentionally
When a case resolves, capture what solved it and how long it took. This builds a personal troubleshooting library for future sessions. Over time, your own notes become more useful than random forum fragments.
I also record which wording produced the first actionable reply. Small communication improvements compound quickly when issues recur over months of play.
✅ Final contact note
Contact recap: one thread, one structure, one escalation ladder. That workflow protects both time and bankroll when friction appears.
🗂️ Extended contact playbook
Case opening standards that reduce delay
The fastest case is usually the one that starts clean. I open with a single-line summary, then add precise fields: amount, method, timestamp, and requested resolution. This structure lets support classify the issue without guesswork. In high-volume queues, classification speed matters as much as agent skill. Vague reports often sit longer because the next action is unclear.
I recommend writing your first message offline for thirty seconds before sending it. That tiny pause removes emotional noise and improves signal density. The best ticket is readable by someone with zero prior context.
Channel selection and escalation order
Do not start everywhere at once. Pick one primary channel and keep all evidence in one thread. If you jump between chat and email with different wording, you create a reconciliation problem for support teams. That can add hours even when everyone is acting in good faith. Structured users get structured outcomes.
My escalation order is simple: primary channel request, bounded wait window, evidence-backed follow-up, then formal escalation with case reference. If a supervisor step is needed, carry the same chronology forward. Never reset the story unless asked.
What to include for payout-related issues
Payout tickets should always include method match context and current verification state. Many delays are not about refusal; they are about missing alignment checks. If you provide this context proactively, support can move straight to adjudication instead of discovery mode.
I also include a concise impact statement: for example, "withdrawal pending beyond stated review window." Impact framing helps teams prioritize operationally without emotional escalation language.
What to include for bonus and wagering issues
Bonus disputes need clause-aware evidence. Include offer snapshot, activation time, and the exact conflict point - max-bet, expiry, exclusion, or contribution mismatch. "Bonus missing" is not enough. Clause-level precision improves both speed and fairness during review.
If possible, attach one clean screenshot per claim rather than a large unstructured dump. Reviewers process clean packets faster than noisy evidence stacks.
Follow-up cadence without spam loops
Frequent follow-ups can feel productive but often degrade outcomes. I follow one rule: each follow-up must add new information. If there is no new data, I wait for the promised window to expire and then escalate once with full context continuity.
This cadence protects relationship quality with support while still preserving urgency. Professional pressure works better than panic pressure over repeated interactions.
Writing style that earns better answers
Support teams respond better to neutral, specific language than to accusation-heavy text. I keep tone factual and assertive: what happened, what was expected, what resolution is requested, and by what timeframe. This makes the conversation auditable and avoids defensive back-and-forth.
When replies are generic, I ask one narrowing question. Narrowing questions force concrete answers and quickly reveal whether escalation is necessary.
Case closure and personal learning loop
After resolution, I capture what worked: message structure, response timing, and escalation trigger point. These notes become a personal operations manual for future incidents. Over time, this habit cuts resolution time because you stop reinventing the process under stress.
I also record what not to repeat - especially wording that led to delays or unclear ownership. Improvement is easier when failures are documented, not forgotten.
Final contact doctrine
Good contact behavior is not about being polite for its own sake. It is about designing communications for rapid triage, clean handoff, and defensible outcomes. The objective is resolution, not expression.
If you remember one rule from this page, make it this: treat every issue as a case file from the first minute. That habit consistently produces faster and clearer outcomes than emotional improvisation.
Brand chart for this page
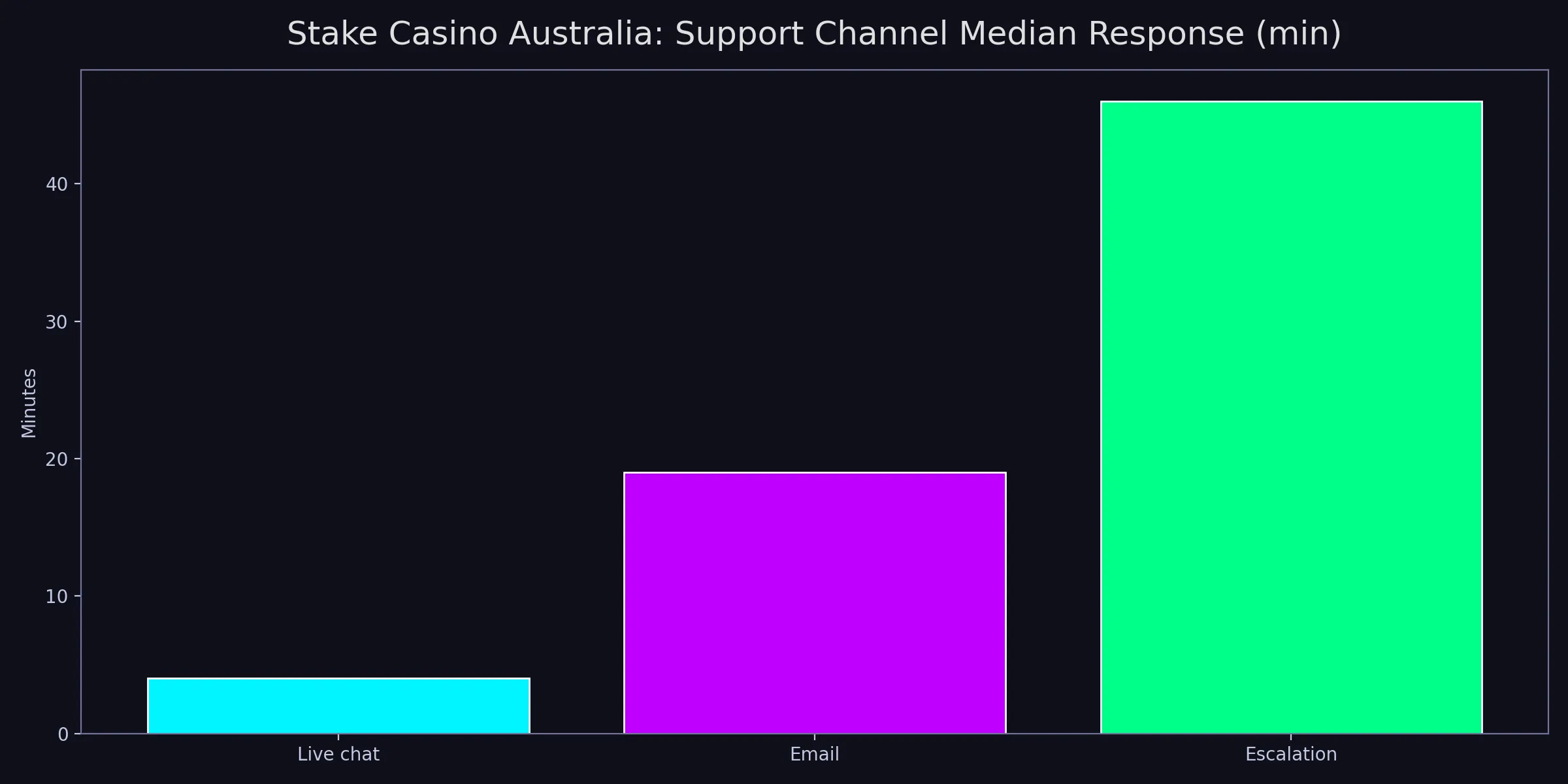
This contact chart is a routing tool, not a promise of identical timings for every case. Response speed depends on message quality, queue load, and evidence completeness. I use it to choose communication order and to set realistic follow-up windows so escalation is assertive but not chaotic.
When readers apply this chart, I suggest one extra step: tag each interaction by channel and outcome quality. Over a few weeks, patterns become visible and you can optimize your own support path. Structured follow-up usually beats repeated channel hopping.
The key lesson is operational: speed without resolution quality is not success. A fast generic reply can waste more time than a slower actionable one. Measure both.
This chart reinforces the same rule as the main page: if process discipline is high, outcomes become more predictable. I read response-time changes as operational feedback on my own communication workflow, not just on support speed. If first response is quick but unhelpful, I mark that as a quality gap rather than a performance win. If response is slower but directly actionable, that usually produces better final resolution time. This distinction matters because many users optimize for speed alone and then get trapped in circular follow-ups.
The second layer is routing quality. I track which channel resolves specific issue classes best: bonus credit mismatches, payout pending states, KYC resubmission loops, and technical round reconciliation. Different channels often behave differently under load. By tagging each case and outcome, I can build a practical routing matrix for future incidents. Over several weeks this matrix becomes more valuable than generic "use chat/email" advice because it is grounded in local evidence from the exact environment I am testing.
I also use this chart section to refine escalation timing. Premature escalation can degrade thread quality, while delayed escalation can prolong holds unnecessarily. My rule is to escalate only when a promised window expires or when new high-signal evidence appears. Each escalation message includes case ID continuity, concise chronology, and one explicit request for ownership or next action. This pattern keeps pressure professional and auditable, which in turn improves consistency across shift handovers.
Another practical insight is that wording structure often outperforms emotional intensity. The same facts framed with tight chronology and explicit asks usually receive clearer responses than long frustrated narratives. That does not mean frustration is invalid; it means communication design should still prioritize triage efficiency. In real operations, readability is a multiplier for resolution speed.
For readers, the reusable method is: classify issue type, choose primary channel, send one structured first message, log response quality, then escalate with continuity only when justified. This is not glamorous, but it works repeatedly. If you apply this cycle across multiple incidents, your average resolution time usually falls and your stress load drops because each case feels less chaotic.
Finally, treat contact performance as a living metric. Queue conditions, staffing, and policy interpretation change. A channel that worked best last month may be weaker this month. Regularly updating your contact playbook keeps expectations realistic and preserves control when stakes are high.
📞 Long-form support operations appendix
This appendix extends the contact methodology for readers who want repeatable escalation outcomes. In support-heavy environments, the difference between resolution and frustration is often communication architecture. Architecture means thread continuity, evidence hierarchy, and escalation timing - not just writing style. When architecture is strong, teams can triage quickly and pass ownership cleanly. When architecture is weak, even good agents lose context.
I structure cases with a fixed order: incident summary, evidence index, requested action, and expected window. This structure mirrors internal support workflows and reduces translation overhead. Instead of forcing agents to infer intent from narrative text, the case arrives with clear decision points. That improves both speed and quality of responses.
Escalation discipline is equally important. Escalating too early creates noise; escalating too late extends avoidable holds. I use explicit thresholds: missed promised window, contradictory guidance, or unresolved high-impact blockers. Each escalation references prior case state and adds new evidence. This keeps pressure legitimate and prevents reset loops that consume time.
I also recommend maintaining a personal support analytics sheet. Track issue type, channel, first useful response time, total resolution time, and final quality rating. After several cases, patterns emerge and you can tune your routing strategy. This is far more effective than relying on generic advice because it reflects your own operational context.
A common failure mode is emotional over-formatting - sending long messages that contain many feelings but few actionable fields. Emotions are valid, but triage still requires precision. I separate emotional processing from case submission: write a draft, cool down briefly, then convert to structured format. This single habit often improves outcomes immediately.
Final appendix note: support communication is a skill that compounds. The more you practice structured case design, the less chaos you experience during high-pressure incidents. Over time, this lowers both financial risk and cognitive fatigue, making sessions safer and more manageable.